
Automating NYC 311 Insights with Airflow, ADF, Terraform and a PostgreSQL Data Warehouse: Transforming the world’s busiest civic service dataset into live, actionable insights
The Story — Why I Built CivicPulse 311
Modern cities run on data. But civic agencies often operate blind.
NYC’s 311 service line receives millions of requests every year — everything from noise complaints to sanitation issues — yet the data typically arrives in analysts’ hands late, unclean, and manually downloaded.
That setup works… until stakeholders need:
-
up-to-date SLA performance
-
borough-level comparisons
-
early indicators of service pressure
-
equity insights across underserved zones
-
automated reporting
Manually refreshing CSV files was no longer acceptable. I built CivicPulse 311 to replicate what a real urban data platform should look like:
-
automated
-
cloud-based
-
resilient
-
incremental
-
transparent
-
multi-layered
-
built with IaC
-
and easy to extend city-wide
A modern city deserves a modern data pipeline — so I built one.
The Core Problem: Slow, Manual, and Outdated Data
Before this solution, analysts faced real limitations:
| Pain Point | Impact | | --- | --- | | Manual CSV downloads | 2–3 hours/week wasted | | No incremental ingestion | Full refresh every time | | Data arrives 24–48 hours late | Poor operational decisions | | Zero infrastructure governance | Drift, errors, inconsistencies | | No real-time dashboards | Leadership always “behind” |
City performance data was locked behind friction. CivicPulse 311 removes that friction — permanently.
Architecture Overview — Engineered Like a Production System
The platform follows a lake → warehouse → dashboard design:
-
Airflow on Astronomer – Extract & serialise 311 data into Parquet
-
Azure Blob Storage – Immutable landing zone
-
Azure Data Factory – High-speed ingestion into staging tables
-
PostgreSQL Warehouse – Clean, deduplicated fact table and views
-
Power BI Dashboards – Real-time service intelligence
-
Terraform IaC – Infrastructure you can redeploy anytime
A full enterprise-grade pipeline — but built entirely with open-source and Azure-native tooling.
How the System Works — Layer by Layer
1. Extract — Airflow Captures the City’s Pulse
Airflow orchestrates incremental pulls from the NYC Open Data API:
-
retrieves the last 90 days
-
handles schema drift
-
rate limits automatically
-
Exports Parquet files to Blob
def fetch_311_to_parquet():
url = NYC_311_URL
df = requests.get(url).json()
table = pa.Table.from_pylist(df)
pq.write_table(table, output_path)
This turns messy JSON into clean, typed Parquet.
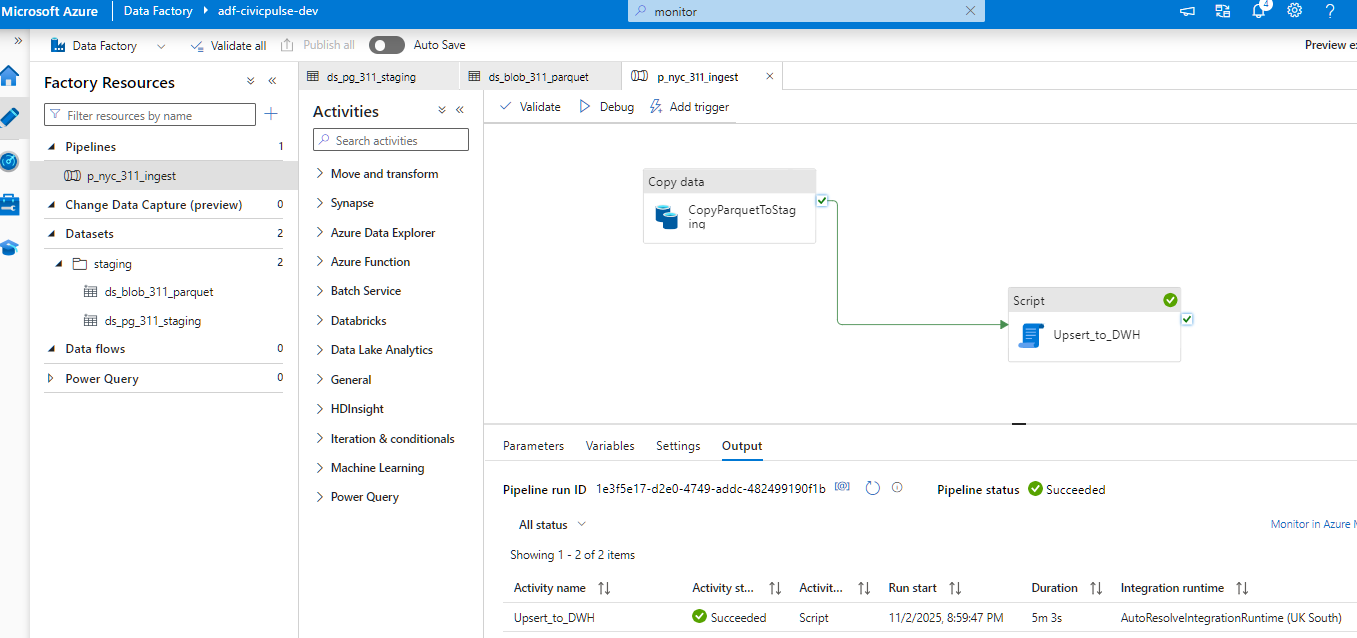
2. Load — ADF Moves Data at Scale
Azure Data Factory handles the heavy lifting:
-
copies Parquet files into
stg.api_311_flat -
logs ingestion runs
-
attaches metadata (ingest timestamp, source file)
-
executes SQL transformations
ADF becomes the backbone of reliable high-volume ingestion.
3. Transform — PostgreSQL Shapes Operational Insight
Raw staging data is transformed into a deduplicated fact table via SQL:
SELECT dwh.run_311_transform(interval '1 hour');
The warehouse logic:
-
deduplicates by
unique_key -
corrects inconsistent timestamps
-
cleans location attributes
-
normalizes agency & complaint fields
-
prepares the dataset for BI
-
applies upsert logic for late-arriving records
The final dataset is clean, explainable, and suitable for analytics.
4. Visualise — Power BI Turns Data into Insight
With clean data ready, dashboards unlock:
-
SLA performance across boroughs
-
Complaint volume trends
-
Agency-level workload
-
Service backlogs & delays
-
Community board comparisons
-
Equity patterns across neighbourhoods
This is where stakeholders finally “see” the city. Power BI transforms the pipeline into a decision-making tool.
Infrastructure as Code — A Real Engineering Touch
Everything — databases, storage accounts, Data Factory, networking — is deployed through Terraform, not manually.
This guarantees:
-
zero configuration drift
-
version-controlled infrastructure
-
reproducibility across environments
-
safe provisioning with state locking
Example:
./scripts/tf_run.sh
One script provisions an entire civic analytics environment.
System Reliability — Designed for Real-World Failures
City systems must run even when:
-
the API rate limits
-
Storage temporarily fails
-
network latency increases
-
Data arrives late or out of order
So I added:
| Layer | Resilience Feature | | --- | --- | | Airflow | retries, watermarking, import checks | | ADF | sequenced activities, logging, fault isolation | | PostgreSQL | UPSERT + dedupe logic | | Terraform | remote state + locking | | Blob Storage | versioned landing zone |
The system is hard to break — and easy to restore.
Runbook — From Zero to Full Platform
1. Deploy Infrastructure
./scripts/tf_run.sh
2. Initialise DB Schema
./scripts/db_apply.sh --all
3. Start Airflow DAG
Hourly extraction begins automatically.
4. Run ADF Pipeline
Parquet → staging → warehouse.
5. Load Power BI
Build visuals on view:dwh.v_311_requests.
Why This Project Matters
CivicPulse 311 isn’t a visualisation exercise. It’s a real data engineering platform with real value. It demonstrates the ability to build:
-
Cloud-native ELT pipelines
-
Production-ready orchestration
-
Enterprise data lake architecture
-
IaC-managed infrastructure
-
Warehouse modelling for operational analytics
-
Real-time dashboards
This is the architecture public-sector agencies actually need.
Future Directions
-
Real-time SLA alerts
-
Merge with sanitation, transit & parks datasets
-
Add geospatial clustering
-
Integrate Azure Monitor observability
-
Build ML-driven complaint topic modelling
The foundation is strong enough to expand into citywide intelligence.
Conclusion — Turning Raw Civic Data Into Operational Clarity
CivicPulse 311 demonstrates how urban data can move from raw JSON to policy-grade intelligence through a pipeline engineered for scale, automation, and reliability.
It’s the type of system civic agencies wish they had — and now, one you can showcase on your website.