
Batch ETL Pipeline (Pyspark , Azure Blob Storage) and Task Scheduler Orchestration (On-Premise)
ETL/ELT/ELTL Automation Project
Project Overview
This project aims to automate the Extract, Transform, Load (ETL), Extract, Load, Transform (ELT), and Extract, Transform, Load, and Loop (ELTL) processes to enhance data pipeline efficiency. By leveraging cloud-based solutions and orchestration tools, the system ensures seamless data integration, transformation, and storage while minimizing manual intervention.
Objectives
-
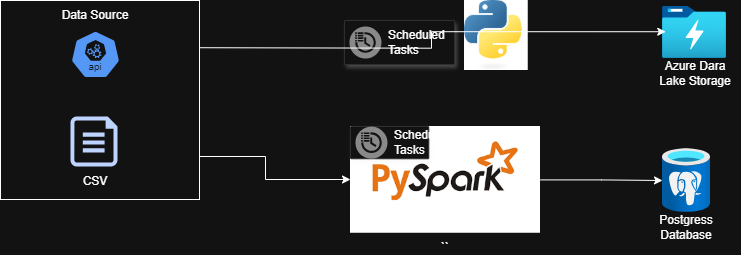
Automate data extraction from multiple sources (databases, APIs, flat files).
-
Optimize transformation processes using scalable frameworks (e.g., Apache Spark,).
-
Enhance data loading efficiency into warehouses like BigQuery, or Azure Synapse.
-
Implement monitoring and error-handling mechanisms for real-time pipeline tracking.
Implementation Approach
-
Data Extraction:
-
Utilize scheduled jobs or event-driven triggers to pull data from structured and unstructured sources.
-
Implement connectors for seamless integration with third-party APIs.
-
-
Data Transformation:
-
Apply schema validation, deduplication, and enrichment techniques.
-
Use parallel processing for large-scale transformations.
-
-
Data Loading:
-
Optimize batch and streaming ingestion methods.
-
Ensure data consistency and integrity through validation checks.
-
-
Looping Mechanism (ELTL):
-
Introduce iterative transformations for dynamic data adjustments.
-
Enable feedback loops for continuous data refinement.
-
Expected Outcomes
-
Reduced processing time through automation.
-
Improved data accuracy with real-time validation.
-
Scalability to accommodate growing datasets and business needs.